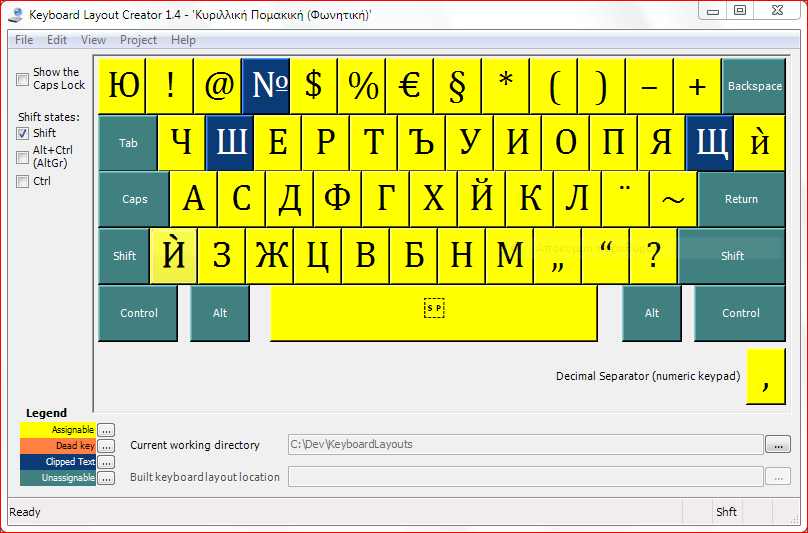
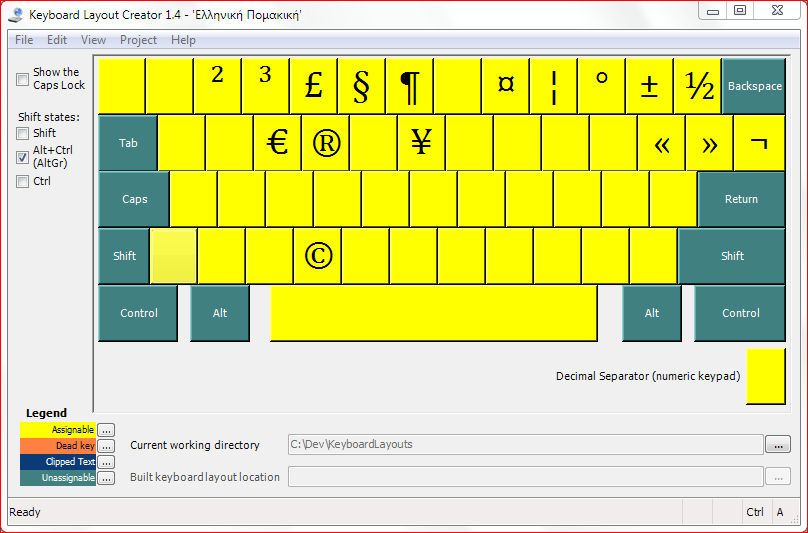
Εδώ και μια δεκαετία περίπου χρησιμοποιώ το κορυφαίο ίσως από κάθε άποψη νοτιοαφρικανικής προέλευσης λεξικογραφικό υπερεργαλείο TshwaneLex για τις καθημερινές και συνηθισμένες εργασίες μου πάνω στο PomLex. Και δεν είναι ότι το συγκεκριμένο εργαλείο δεν παρέχει τη δυνατότητα προσαρμοσμένης ταξινόμησης. Την παρέχει και με τον καλύτερο τρόπο ίσως. Αλλιώς τί σόι εργαλείο θα ήταν; Απλώς η δυνατότητα αυτή παρέχεται σε επίπεδο λήμματος. Για πολύ εξειδικευμένες εργασίες όμως, όπως η ενδολημματική ταξινόμηση σε μια δενδροειδή δομή ενός λήμματος της παρακάτω μορφής, τα πράγματα γίνονται αρκετά περίπλοκα.

Αυτό, βέβαια, μέσα από το περιβάλλον του TshwaneLex. Αν τώρα θελήσει κανείς να μεταφέρει την εργασία του εκτός περιβάλλοντος TshwaneLex και να χρησιμοποιήσει εργαλεία δικά του ή τρίτων κατασκευαστών για περαιτέρω επεξεργασία τί γίνεται; Στην περίπτωση της Πομακικής άμεση υποστήριξη, απλά, δεν παρέχεται από κανέναν. Η δε έμμεση συναρτάται με την ατομική πρωτοβουλία και δυνατότητα αλλά και τους στόχους που έχει ο καθένας.
Η δωρεάν και ανοιχτού κώδικα βιβλιοθήκη ICU (International Components for Unicode) της IBM είναι μια απ’ αυτές που χρησιμοποιείται ευρέως από τους προγραμματιστές για τον χειρισμό κειμένου Unicode. Μερική χρήση των δυνατοτήτων της βιβλιοθήκης μπορεί να κάνει και το SQLite για την ταξινόμηση, αν του το ζητήσει κανείς (μεταγλώττιση με την αντίστοιχη επιλογή - ενεργοποίηση). Αυτή θα ήταν μια καλή λύση ομολογώ, έστω και μεσοβέζικη, αν, βεβαίως, ήμουν γκουρού της C και μπορούσα να το θέσω σε λειτουργία αυτό το πράγμα. Η αλήθεια είναι ότι αποπειράθηκα, ασχέτως αποτελέσματος.
Η επόμενη κίνηση ήταν να δοκιμάσω την απ’ ευθείας χρήση της βιβλιοθήκης μέσα από τα δικά μου C++ εργαλεία. Τα πρώτα αποτελέσματα δεν άργησαν να φανούν και ήταν ό,τι ακριβώς έψαχνα. Προσαρμοσμένη ταξινόμηση, ανεξάρτητη από λειτουργικά συστήματα, λεξικογραφικά εργαλεία, επεξεργαστές κειμένου κλπ. Να ‘ναι καλά όλοι αυτοί οι άνθρωποι που δούλεψαν για το ICU.



Κάποια άλλη φορά θα γράψω για τον συλλαβισμό και θα σας δώσω μια μίνι εφαρμογή επίδειξης των δυνατοτήτων ταξινόμησης και συλλαβισμού της Πομακικής.

Αυτό, βέβαια, μέσα από το περιβάλλον του TshwaneLex. Αν τώρα θελήσει κανείς να μεταφέρει την εργασία του εκτός περιβάλλοντος TshwaneLex και να χρησιμοποιήσει εργαλεία δικά του ή τρίτων κατασκευαστών για περαιτέρω επεξεργασία τί γίνεται; Στην περίπτωση της Πομακικής άμεση υποστήριξη, απλά, δεν παρέχεται από κανέναν. Η δε έμμεση συναρτάται με την ατομική πρωτοβουλία και δυνατότητα αλλά και τους στόχους που έχει ο καθένας.
Η δωρεάν και ανοιχτού κώδικα βιβλιοθήκη ICU (International Components for Unicode) της IBM είναι μια απ’ αυτές που χρησιμοποιείται ευρέως από τους προγραμματιστές για τον χειρισμό κειμένου Unicode. Μερική χρήση των δυνατοτήτων της βιβλιοθήκης μπορεί να κάνει και το SQLite για την ταξινόμηση, αν του το ζητήσει κανείς (μεταγλώττιση με την αντίστοιχη επιλογή - ενεργοποίηση). Αυτή θα ήταν μια καλή λύση ομολογώ, έστω και μεσοβέζικη, αν, βεβαίως, ήμουν γκουρού της C και μπορούσα να το θέσω σε λειτουργία αυτό το πράγμα. Η αλήθεια είναι ότι αποπειράθηκα, ασχέτως αποτελέσματος.
Η επόμενη κίνηση ήταν να δοκιμάσω την απ’ ευθείας χρήση της βιβλιοθήκης μέσα από τα δικά μου C++ εργαλεία. Τα πρώτα αποτελέσματα δεν άργησαν να φανούν και ήταν ό,τι ακριβώς έψαχνα. Προσαρμοσμένη ταξινόμηση, ανεξάρτητη από λειτουργικά συστήματα, λεξικογραφικά εργαλεία, επεξεργαστές κειμένου κλπ. Να ‘ναι καλά όλοι αυτοί οι άνθρωποι που δούλεψαν για το ICU.


Κάποια άλλη φορά θα γράψω για τον συλλαβισμό και θα σας δώσω μια μίνι εφαρμογή επίδειξης των δυνατοτήτων ταξινόμησης και συλλαβισμού της Πομακικής.